 Matthew Wilkens
Matthew Wilkens
Associate Professor of English Matthew Wilkens is fascinated by the use of geography in literature over time. How, for example, did the Civil War affect the importance of certain places in American literature, and what can literature tells us about Americans’ sense of place?
The answer can be found in books written during that period — potentially thousands of them, many more than Wilkens could ever read and analyze himself.
To consider the widest possible range of literary production, Wilkens turned to computation. He was recently awarded a $325,000 Digital Humanities Implementation Grant from the National Endowment for the Humanities to bolster Textual Geographies, a database and suite of tools he is developing that allow users to find, map, and analyze more than 14 billion place name mentions from books and journals in English, Spanish, German, and Chinese.
“I’m very pleased to receive this grant,” he said. “It’s nice to be able to bring new partners into the project and to have the funds and resources to work with — things that would be much more difficult to do without that financial backing.”
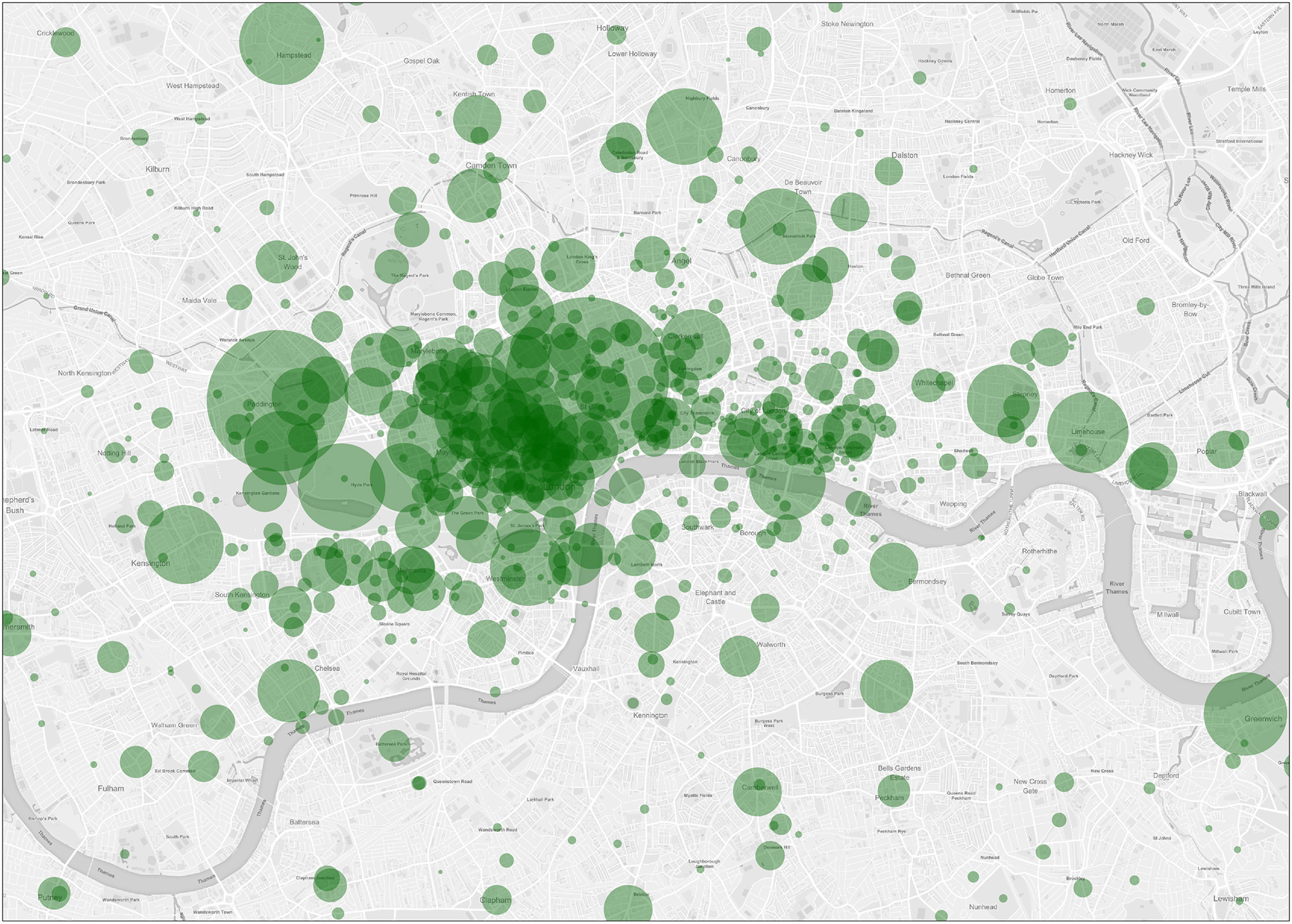 This map of London, showing locations mentioned in British fiction published between 1880 and 1940, shows one potential use of Textual Geographies.
This map of London, showing locations mentioned in British fiction published between 1880 and 1940, shows one potential use of Textual Geographies.
Textual Geographies draws its data from HathiTrust, a digital database of more than 100 institutions’ library holdings, many of which were originally scanned for Google Books. In 2014, with support from an American Council of Learned Societies fellowship, Wilkens mined HathiTrust’s public-domain texts — about four million volumes published before 1923 — for place name mentions.
With the NEH grant, Wilkens is able to expand the project. Significantly, he’ll add an additional six million in-copyright volumes to the database. Collaborating with postdoctoral fellow Dan Sinykin and the Notre Dame Center for Research Computing, he’s also developing tools that make the terabytes of data accessible to scholars who don’t have backgrounds in programming or data analysis.
“They can quickly say, ‘show me how many mentions there are of locations in France in the following kinds of books written by women between 1940 and 1970, and compare that to the same demographic after 1970,” Wilkens said. “It’s an impossible question to answer by conventional means.”
 A map of U.S. states that were underrepresented in literature relative to their population around the time of the Civil War.
A map of U.S. states that were underrepresented in literature relative to their population around the time of the Civil War.
Charting changes in place name mentions across literary production can give scholars an even better picture of changes in culture over time — Wilkens is using the database to research a book on the literary geography of the United States, among other projects.
He’s already used large-scale analysis to provide new insight on American literature after the Civil War. In a study of place name mentions in books published between 1851 to 1875, Wilkens found that literary interest in certain places didn’t change after the war as quickly as previously thought.
“In the evidence we saw that America as a unified entity certainly didn’t emerge as quickly or as straightforwardly as that story might have led us to believe,” he said.
Textual Geographies adds a new tool to a growing field within literary studies, of which Wilkens is a notable leader. He is also the president of the Digital Americanists Society and a co-investigator on “Text Mining the Novel,” a project that aims to understand the novel’s place in society through quantitative methods.
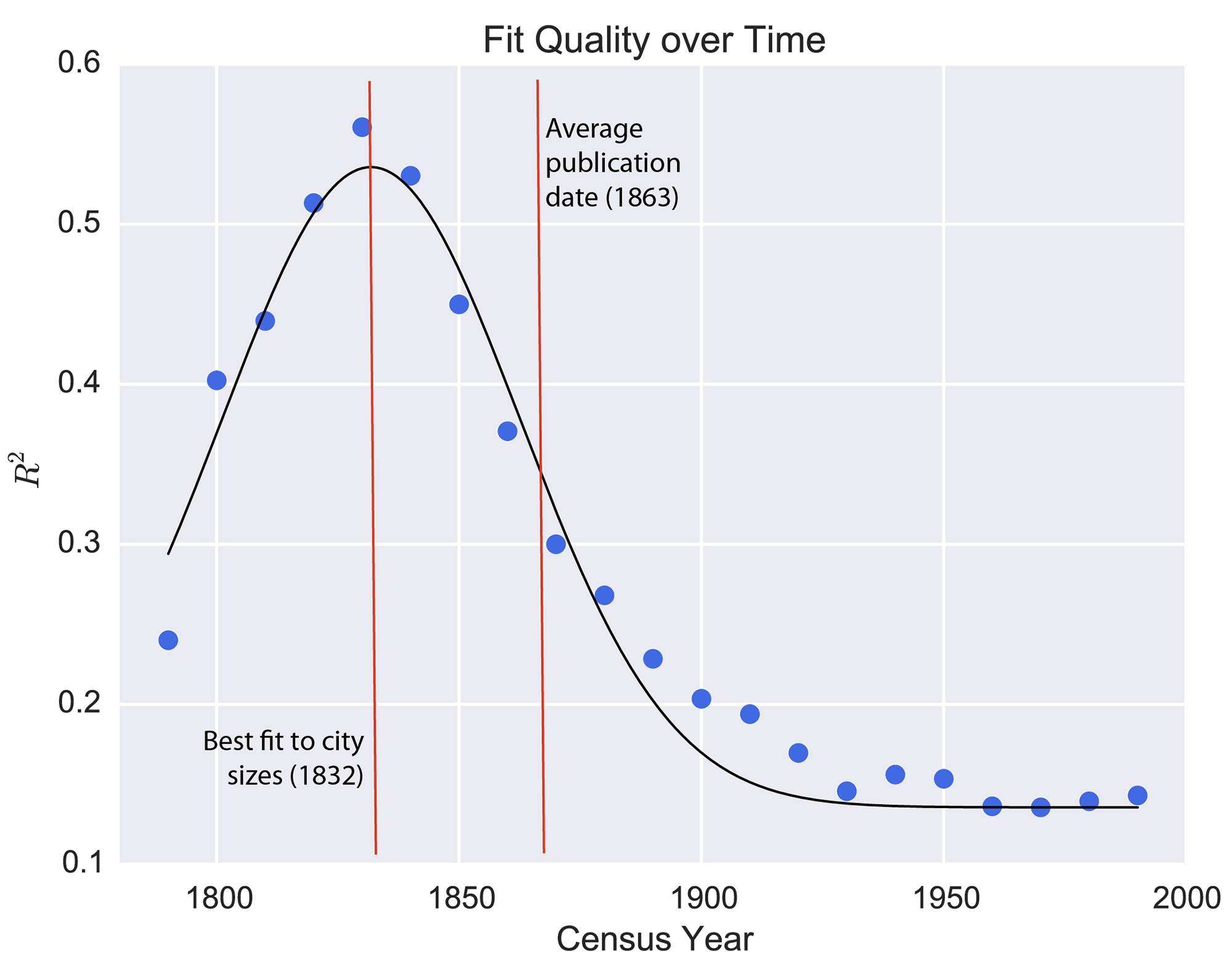 This graph, developed with Textual Geographies, illustrates the lag time between changes in U.S. city populations and corresponding changes in literary usage rates. In other words, if a lot of people move west, how long does it take for authors to start writing about western locations en masse? In this case, about 30 years.
This graph, developed with Textual Geographies, illustrates the lag time between changes in U.S. city populations and corresponding changes in literary usage rates. In other words, if a lot of people move west, how long does it take for authors to start writing about western locations en masse? In this case, about 30 years.
Those methods have become all the more important over the past few generations, as literature is increasingly thought of as “socially symptomatic,” Wilkens said.
“If we say, ‘what does the fact that this book existed with these features, in this form, tell us about the culture that produced it,’ the obvious followup to that is, ‘what about all the books?’” Wilkens said.
Combining computational analysis with traditional literary analysis, Wilkens said, allows scholars to more fully understand how literature reflects — or influences — the time and place in which it was published and the people who read it.
“Those two kinds of evidence potentially play together really well, the kind of evidence that we get from close reading and literary hermeneutics coupled with this large scale, trend-based evidence,” Wilkens said. “I try to use both kinds of evidence in my own work. I think a lot of the best computational and quantitative work in the humanities likewise uses both.”


